Table of contents
機械学習 (Machine Learning)
教師あり学習 (Supervised learning)
まず、入出力関係を定義しましょう。
\[y = f(\mathbf{x}) \tag{4.1}\]ここで\(\mathbf{x}\)は入力(Input)、\(y\)は出力(Output)です。例えば、入力が画像データ、出力がその画像に写っている動物とすると、この関数\(f\)は動物を判定するための関数であることがわかります。この分類を機械に任せたいというのが、機械学習の目標です。言い換えれば、関数\(f\)を真似した人工的な関数\(g\)を作ることが目標となります。
\[y \simeq g(\mathbf{x}) (\simeq f(\mathbf{x})) \tag{4.2}\]関数\(f\)を真似するために\(g\)を様々変化させることを、機械学習で行います。しかし真の\(f\)はわからないので、その指標として入力と出力の結果(やその関係性)を用います。真似るための指標(教師)として、データセットを最初に提供します。
\[D = (\mathbf{x}_\mu, y_\mu) \qquad (\mu = 1, 2, \cdots , M) \tag{4.3}\]Loss function (error, 損失関数、誤差関数)
機械学習の結果が間違っているかどうかを、人間側が指導する必要があります。これをLoss functionと呼びます。これには決まった定義はなく、最終的に答えを出す人間が適切に決定します。例として、以下のようなものがあります。
\[\min_{g} \left\{ \frac{1}{2} \sum_{\mu = 1}^2 (y_\mu - g(\mathbf{x}_\mu))^2 \right\} \tag{4.4}\]データセットとして与えられている答え\(y_\mu\)と機械が予測した結果\(g(\mathbf{x}_\mu)\)の差を全ての添字に対して和を撮ったものが、最小になるように関数\(g\)を最適化することが、機械学習の目標となります。関数\(f\)は皆目見当がつかないものですが、とりあえず\(g\)をモデルとして用意して後から結果に合うように\(g\)を合わせます。
変える余地のある(パラメータを多数持つような)関数を最適化するのが深層学習です。厳密な物理・数学の世界からみたら愚の骨頂?
深層学習を用いて問題を解くことで、我々は賢くなったのでしょうか?答えは否。ただし深層学習を用いて出てきた結果を考察することで次のステップに行くことができます。どんな関数なら上手くいくのかを解析することもできるでしょう。これはデータサイエンス研究手法の新しい形です。
上述のように、機械学習は1. \(g(\mathbf{x})\)を定義する、2. Loss functionを定義する、3. 最適化する、という手順で行います。
Perceptron (パーセプトロン)
最初のstepとして、パーセプトロンを考えましょう。これは統計力学におけるIsing modelのように、機械学習や人工知能におけるトイモデルとして広く知られています。
\[y_\mu = f(\mathbf{x}_\mu) \qquad (y \in \{ -1, +1\}) \tag{4.5}\]を真似るものとして
\[y_\mu \simeq \mathrm{sign} (\mathbf{w}^T \mathbf{x}_\mu) \tag{4.6}\]を考えます。これは以下のように入力層と出力層で図示することができます。
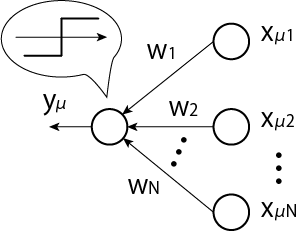
機械学習で行っているのは入力データに対して線形変換と非線形変換を繰り返しです。これにより複雑な関数を形成することができます。
次に(4.5), (4.6)式がどれくらい似ているかを決めましょう。一例として、以下のようなものが考えられます。
\(y_\mu\)の符号と\(\mathrm{sign} (\cdots)\)の符号が一致していれば良いので、これの和にマイナスをつけたものが最小となるように最適化すれば良いことがわかります。
これを見てわかるように、このLoss functionは物理学で言うところのエネルギー\(E(\mathbf{w})\)と見なすことができます。\(\mathbf{w}\)は物理系の自由度を表現していると言えるでしょう。その意味では機械学習の系を最適化することは、我々のコンピュータを冷凍機としてその人工的な系のエネルギーを最小化することと同義です。このような理由から低温物理学や統計物理学とのアナロジーが使えることがわかります。
同様の考え方から、量子機械学習を考えるのは至極当然の流れと言えるでしょう。
Statistical Mechanics
以下では単純に入力データがガウス分布に従うとしましょう。
\[P (\mathbf{x}_\mu) = \sqrt{\frac{N}{2\pi}} \exp \left( -\frac{N}{2} \mathbf{x}_\mu^T \mathbf{x}_\mu \right) \tag{4.8}\]ここで\(N\)はベクトルの成分の数、\(M\)はデータの数です。そして、\(y_\mu\)は{-1, 1}の分布しか持たないような分布を考えます。
\[P(y_\mu) = \frac{1}{2} \{\delta (y_\mu -1) + \delta (y_\mu + 1) \} \tag{4.9}\]今、考えているのは(4.7)式のように大きさを考えない系なので、\(\mathbf{w}^2 = N\)のように規格化されているものとして以降の計算を行います。すると分配関数は
\[Z = \int d\mathbf{w} \delta (\mathbf{w}^T \mathbf{w}-N) \exp \left( \sum_{\mu = 1}^M \beta y_\mu \mathrm{sign} (\mathbf{w} \cdot \mathbf{x}_\mu)\right) \tag{4.10}\]\(y, x\)を固定した(quench randomnesした)元で\(w\)について最適化することを考えます(\(y, x\)は教師データなので予め与えられたものであることから)。すると\(x, y\)は固定されたスピンと考えることができるので、これはスピングラスの理論(レプリカ法)で計算を進めることができます。
このような系はquenched系ですが、y, w, xが全て同時に動く場合にはannealed系です。前者はデータを与えきった後に学習を行う「オフライン学習」、後者はデータを与えるたびに$$w$$が変化するような学習を「オンライン学習」に対応します。計算したい系によって計算テクニックを使い分けます。
ではレプリカ法を用いて計算を行っていきましょう。
\[[Z^n]_D = \prod_a \int d\mathbf{w}_a \delta (\mathbf{w}_a^T \mathbf{w}_a -N) \prod_{\mu=1}^M \left[ \exp (\beta y_\mu \mathrm{sign} (\mathbf{w}_a^T \mathbf{x}_\mu)) \right]_{y_\mu, \mathbf{x}_\mu} \tag{4.11}\]\(u_\mu^{a=1, 2, \cdots, n}\) property
ここで\(u_\mu^a \equiv \mathbf{w}_a \cdot \mathbf{x}_\mu\)を定義します。この変数が従う確率分布を計算してみましょう。
\[P (\mathbf{u}_\mu) = \int d\mathbf{x}_\mu P(\mathbf{x}_\mu) \prod_a \delta (u_\mu^a - \mathbf{w}_a \cdot \mathbf{x}_\mu) = \int d\mathbf{x}_\mu \exp \left( -\frac{N}{2} \mathbf{x}_\mu^T \mathbf{x}_\mu + i \sum \tilde{u}_\mu^a (u_\mu^a - \mathbf{w}_a \cdot \mathbf{x}_\mu)\right) \tag{4.12}\]\(e\)の肩を計算しましょう。
\[-\frac{N}{2} \left( \mathbf{x}_\mu-i \sum_a \tilde{u}_\mu^a \frac{\mathbf{w}_a}{N} \right)^2 - \frac{1}{2N} \left( \sum_a \tilde{u}_\mu^a \mathbf{w}_a \right)^2\]より、(4.12)式は\(\mathbf{x}_\mu\)での積分が実行できて
\[P(\mathbf{u}_\mu) \propto \int \tilde{u}_\mu^a \exp \left( -\frac{1}{2N} \sum_{a, b} \tilde{u}_\mu^a (\mathbf{w}_a^T \mathbf{w}_b) \tilde{u}_\mu^b + i \sum_a u_\mu^a \tilde{u}_\mu^a \right) \propto \exp \left( - \frac{1}{2} \sum_{a, b} u_\mu^a (Q^{-1})_{ab} u_\mu^b \right) \tag{4.13}\]ここで\(q_{ab} \equiv \frac{1}{N} \mathbf{w}_a^T \mathbf{w}_b\)はこの系のスピングラス秩序パラメータ、\(Q = (q_{ab})\)はその行列です。(4.13)式の形から、\(u_\mu^a\)は平均0、分散\(q_{ab}\)のガウス分布に従うことがわかります。これは中心極限定理と同じ形です。
Equivalence representation
等価定理による表現は以下のようなものでした。
\[[f(\mathbf{u}_\mu)]_{\mathbf{x}_\mu, y_\mu} = \left[ \int d\mathbf{u}_\mu P(\mathbf{u}_\mu) f(\mathbf{u}_\mu) \right]\]これより
\[[Z] = \int dQ \prod_a \int d\mathbf{w}_a \prod_\mu \left[ \int d\mathbf{u}_\mu P(\mathbf{u}_\mu) \prod_a \exp (\beta y_\mu \mathrm{sign}(u_\mu^a))\right]_{y_\mu} \times \prod_{a, b} \delta (N q^{ab} - \mathbf{w}_a \cdot \mathbf{w}_b) \tag{4.14}\]このようにすることで\(u\)の積分と\(w\)の積分に分けることができます。すると\(\prod_a \int d\mathbf{w}_a \prod_{a, b} \delta(Nq^{ab}-\mathbf{w}_a \cdot \mathbf{w}_b)\)の部分は、これまで計算してきたものと同じくエントロピーを表しているとわかります。これまでの計算と違いが現れているのは\([\cdots]_{y_\mu}\)の部分のみです。エネルギーの部分を\(e^{-N\beta e(Q)}\)、エントロピー部分を\(e^{NS(Q)}\)とおくと
\[[Z] = \int dQ \exp (-N \beta e(Q) + N S(Q))\]となります。
エネルギーの計算
それではエネルギーの計算を進めていきましょう。
\[-\beta e(Q) = \frac{1}{N} \log \prod_{\mu} \left[ \int d\mathbf{u}_\mu P(\mathbf{u}_\mu) \prod_{a=1}^n e^{\beta y_\mu \mathrm{sign} (u_\mu^a)} \right]_{y_\mu} \tag{4.15}\]ここで\(u_\mu^a\)の平均が0, 分散が\(q^{ab} = \frac{1}{N} \mathbf{w}_a \mathbf{w}_b\)ということと、レプリカ対称性
\[Q = \left( \begin{array}{cccc} 1 & q & \cdots & q \\ q & 1 & \ddots & \vdots \\ \vdots & \ddots & \ddots & q\\ q & \cdots & q& 1 \end{array} \right)\]より\(u_\mu^a = \sqrt{q} z + \sqrt{1-q} x_a\)と表現することができます。ここで\(z, x_a\)は(0,1)のガウス分布に従う変数です。すると
\[[u_\mu^a] = 0\] \[\begin{aligned} [u_\mu^a u_\mu^b] &= [(\sqrt{q} z + \sqrt{1-q} x_a)(\sqrt{q} z + \sqrt{1-q} x_b)] = [q z^2] + \sqrt{q(1-q)} [z(x_a+x_b)] + (1-q) [x_a x_b] \\ &= q + (1-q) \delta_{ab} \end{aligned}\]となります。よって\(u_\mu^a\)を\(z, x_a\)で書き換えましょう。
\[-\beta e(Q) = \frac{M}{N} \log \left[ \int D_z \left( \int D_x \exp (\beta y_\mu \mathrm{sign}(\sqrt{q}z + \sqrt{1-q}x))\right)^n \right]_{y_\mu} \tag{4.16}\]\(n\)乗は\(a = 1, 2, \cdots, n\)の場合の計算が全て一致することから出てきます。
機械学習の一般形として、エネルギーを\(e^{-\beta f(\mathbf{w} \cdot \mathbf{x}_\mu)}\)と書くことができます。これは線形変換と非線形変換を施した形になっているため、これが一般形になっていることがわかります。これまでの議論から\(u_\mu^a = \mathbf{w}_a \cdot \mathbf{x}_\mu\)と書け、これはさらに等価定理で\(z, x_a\)で表現することができます…という議論の進め方を(公式のように)覚えてしまえば、あとは手を動かすだけで研究ができます。
(4.18)式の変形をさらに進めます。
\((\cdots)\)の中を整理しましょう。被積分関数の中にsignがあるので、場合分けが必要です。
\[\int_{-\infty}^{-\sqrt{\frac{q}{1-q}} z} D_x e^{-\beta y_\mu} + \int_{-\sqrt{\frac{q}{1-q}} z}^\infty D_x e^{\beta y_\mu} \tag{4.18}\]相補誤差関数
\[H(x) = \int_x^\infty D_z \tag{4.19}\]を用いると
\[H(-x) = \int_{-x}^\infty D_z = \int_{-\infty}^\infty D_z - \int_{-\infty}^{-x} D_z \underbrace{=}_{z \rightarrow -z} 1 + \int_\infty^x D_x = 1 - H(x) \tag{4.20}\]より
\[\begin{align} (4.18) &= e^{\beta y_\mu} H \left( - \sqrt{\frac{q}{1-q}} z\right) + \left( \int_{-\infty}^\infty D_z - \int_{-\sqrt{\frac{q}{1-q}} z}^\infty D_z\right) e^{-\beta y_\mu} \notag \\ &= e^{\beta y_\mu} H \left( -\sqrt{\frac{q}{1-q}} z \right) + e^{-\beta y_\mu} \left( 1- H \left( -\sqrt{\frac{q}{1-q}} z\right)\right) \notag \\ &= e^{\beta y_\mu} \left( 1- H \left( \sqrt{\frac{q}{1-q}} z\right)\right) + e^{-\beta y_\mu} H\left( \sqrt{\frac{q}{1-q}} z\right) \tag{4.21} \end{align}\]となります。以上より
\[-\beta e(Q) = \alpha n \left[ \int D_z \log (e^{-\beta y_\mu} H + e^{\beta y_\mu} (1-H)) \right]_{y_\mu} \tag{4.22}\]ここで\(\alpha \equiv M/N, H \equiv H (\sqrt{\frac{q}{1-q}} z)\)です。
エントロピーの計算
残りのエントロピーの計算を行いましょう。
\[\begin{align} &\prod_{a=1}^n \int d\mathbf{w}_a \prod_{a\neq b} \delta (Nq - \mathbf{w}_a^T \mathbf{w}_b) \prod_a \delta (N- \mathbf{w}_a^T \mathbf{w}_a) \notag \\ &= \prod_a \int d\mathbf{w}_a \int d\tilde{Q} \int d\tilde{q} \exp \left( \frac{1}{2} \tilde{Q} \sum_a (N-\mathbf{w}_a \mathbf{w}_a)\right) \exp \left( -\frac{\tilde{q}}{2} \sum_{a\neq b} (Nq - \mathbf{w}_a \cdot \mathbf{w}_b)\right) \tag{4.23} \end{align}\]\(e\)の肩の部分を整理すると
\[\frac{1}{2} nN \tilde{Q} - \frac{1}{2} \tilde{q} q N n(n-1) - \frac{\tilde{Q}}{2} \sum_a \mathbf{w}_a \cdot \mathbf{w}_a + \frac{\tilde{q}}{2} \sum_{a \neq b} \mathbf{w}_a \cdot \mathbf{w}_b \tag{4.24}\]最後の項を整理すると
\[\frac{\tilde{q}}{2} \left\{ \left( \sum_a \mathbf{w}_a\right)^2 - \sum_a \mathbf{w}_a^2\right\} \tag{4.25}\]この\((\sum_a \mathbf{w}_a)^2\)の部分にHubbard-Stratonovich変換をして\(\sqrt{\tilde{q}}\mathbf{z} \sum_a \mathbf{w}_a\)とすると
\[(4.23) = \int D_z \prod_{a=1}^n \int d\mathbf{w}_a \int d\tilde{Q} \int d\tilde{q} \exp \left( nN \left( \frac{1}{2} \tilde{Q} + \frac{1}{2} q \tilde{q} \right) \right) \exp \left( -\frac{1}{2} (\tilde{Q} + \tilde{q}) \sum_a \mathbf{w}_a \cdot \mathbf{w}_a + \sqrt{\tilde{q}} \mathbf{z} \sum_a \mathbf{w}_a \right) \tag{4.26}\]上式において\(\prod_a \int d\mathbf{w}_a \exp (\cdots)\)の部分でガウス積分を実行すると\(\left( \sqrt{\frac{2\pi}{\tilde{Q} + \tilde{q}}} \exp \left( \frac{\tilde{q} \mathbf{z}^2}{2(\tilde{Q} + \tilde(q))}\right)\right)^{nN}\)となります。計算していくと
\[S(Q) = \frac{1}{N} \log \prod_a \int d\mathbf{w}_a \cdots = \frac{n}{2} (\tilde{Q} + q \tilde{q}) - \frac{n}{2} \log(\tilde{Q} + \tilde{q}) + \frac{n}{2} \frac{\tilde{q}}{\tilde{Q} + \tilde{q}} \tag{4.27}\]エントロピーに鞍点法を適用
\[\frac{\partial S}{\partial \tilde{Q}} = \frac{1}{2} - \frac{1}{2} \frac{1}{\tilde{Q} + \tilde{q}} - \frac{1}{2} \frac{\tilde{q}}{\tilde{Q} + \tilde{q}} = 0 \ \Longrightarrow \ \therefore \ 1 = \frac{1}{\tilde{Q} + \tilde{q}} + \frac{\tilde{q}}{(\tilde{Q} + \tilde{q})^2} \tag{4.28}\] \[\frac{\partial S}{\partial \tilde{q}} = \frac{1}{2} q - \frac{\tilde{q}}{2 (\tilde{Q} + \tilde{q})^2} = 0 \ \Longrightarrow \ \therefore \ q = \frac{\tilde{q}}{(\tilde{Q} + \tilde{q})^2} \tag{4.29}\]以上より
\[1-q = \frac{1}{\tilde{Q} + \tilde{q}}, \ q = (1-q^2) \tilde{q} \tag{4.30}\]という恒等式を得ます。
エネルギーに鞍点法を適用
(4.21)式よりエネルギーは以下のように書けたのでした。
\[-\beta e(Q) = \alpha n \int D_z \log(e^{-\beta} H + e^{\beta}(1-H))\]ここで\(H = H (\sqrt{\frac{q}{1-q}}z)\)です。logの中身を\(Y\)と定義すると、エントロピー項から\(\frac{1}{2} q \tilde{q}\)が出てくることを合わせて
\[\frac{\partial e}{\partial q} = \frac{1}{2} \tilde{q} + \alpha \int D_z \frac{1}{Y} \left[ e^{-\beta} - e^\beta \right] H' \left( \frac{1}{2} \frac{z}{\sqrt{q} \sqrt{1-q}} + \frac{1}{2} \frac{\sqrt{q}z}{(1-q)^{3/2}}\right) = 0 \tag{4.31}\]ここで
\[\int D_z z f(az) = \int D_z a f'(az)\]を用いると
\[\begin{align} &\frac{\partial e}{\partial q} = \frac{1}{2} \tilde{q} + \frac{\alpha}{2} \int D_z \left[ \frac{e^{-\beta}-e^\beta}{Y} H'' \left( \frac{1}{1-q} + \frac{q}{(1-q)^2}\right) - \frac{1}{Y^2} (e^{-\beta} -e^\beta)^2 (H')^2 \left( \frac{1}{1-q} + \frac{q}{(1-q)^2}\right)\right] = 0 \notag \\ &\Longrightarrow \ \tilde{q} = - \frac{\alpha}{(1-q)^2} \int D_z \left[ \frac{1}{Y} (e^{-\beta} - e^\beta) H'' - \left( \frac{1}{Y} (e^{-\beta} - e^\beta) H' \right)^2\right] \tag{4.32} \end{align}\](4.30), (4.32)式より
\[q = -\alpha \int D_z \left[ \frac{1}{Y} (e^{-\beta} - e^\beta) H'' - \left( \frac{1}{Y} (e^{-\beta} - e^\beta) H' \right)^2\right] \tag{4.33}\]これは\(q\)についての自己無撞着方程式になっています。この式において\(\beta \rightarrow \infty\)を考えましょう。すると\(Y = e^{-\beta} H + e^\beta (1-H)\)より
\[q \rightarrow \alpha \int D_z \left( \frac{H''}{1-H} - \left( \frac{H'}{1-H}\right)^2\right) \tag{4.34}\]となります。\(\beta \rightarrow \infty\)極限の\(q\)を横軸\(\alpha\)で図示すると以下のようになります。
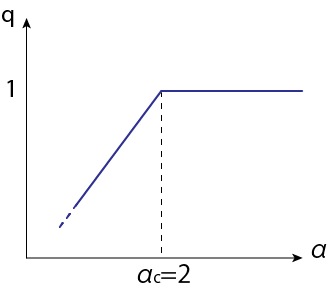
この図の再現ができない...どこかで計算ミス?それとも作成したスクリプトのアルゴリズムの問題?
この図から、\(\alpha > 2\)でスピン秩序パラメータが\(q=1\)に凍結することを表しています。ここで\(q = \frac{1}{N} \mathbf{w}_a \mathbf{w}_b\)です。この意味を考えるために、2種類のデータを分類することを考えましょう。\(\alpha = M/N\)より、\(\alpha\)はデータの数に比例しています。これが大きいとデータ分類の境界線がある狭い領域にのみ現れるようになり、同じ答えしか出せなくなります。これはパーセプトロンの性能限界を表していることがわかります。
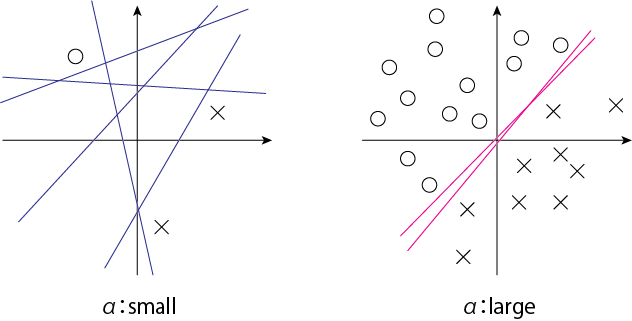
Hidden Manifold Model (arXiv: 2002.09339)
これまで行ってきた計算には実は大問題があります。
古典的なモデル
入力データがガウス分布に従っているとして
\[P (\mathbf{x}_\mu) = \sqrt{\frac{N}{2\pi}} \exp \left( - \frac{1}{2N} \mathbf{x}_\mu^T \mathbf{x}_\mu \right)\]さらに出力は
\[P(y_\mu) = \frac{1}{2} (\delta (y_\mu -1) + \delta (y_\mu + 1) ) \ \mathrm{or} \ y_\mu = \left\{ \begin{array}{ll} \mathrm{sign} (\mathbf{w}_0^T \mathbf{x}_\mu) & (\mathrm{Teacher}) \\ \mathrm{sign} (\mathbf{w}^T \mathbf{x}_\mu) & (\mathrm{Student}) \end{array} \right.\]のように、教師モデルを模倣して生徒もモデルを考えます。これは古典的なモデルとして、1990年代にたくさん計算されました。
現実的なモデル
しかし、現実は異なります。古典的な方法論に従って、複雑なモデルがたくさん生み出されました。しかし、それはこの機械学習の本質ではなく、これは現実を表すための重要な側面とは言えませんでした。重要なのはデータです。これまでの計算で用いられてきたランダムな分布のデータというものは本来ありえません(例えば、猫の画像は猫の構造を持っており、その時点でランダムではありません)。
\(x, y\)は何かしらの相関を持っており、そのような関係性がないデータを学習しても意味がありません。Hidden Manifold Modelとは\(x, y\)が何かしらの鍵を用いて生成されていると考えます。

簡単なものとして以下のようなものがあります。入力は
\[\mathbf{x}_\mu = \sigma \left( \frac{1}{\sqrt{d}}F \cdot \mathbf{C}_\mu \right) \qquad (F \in \mathbb{R}^{d \times \rho}, \mathbf{C} \in \mathbb{R}^\rho) \tag{4.35}\]そして出力は、入力と相関する形として
\[y_\mu = f\left( \frac{1}{\sqrt{d}} \mathbf{C}_\mu^T \mathbf{w}_0 \right) \tag{4.36}\]本質的なものは深い複雑な構造にあるのではなくて、データの相関にあるということを覚えておきましょう。
機械学習が上手くその性能を発揮しない背景には、入力と出力の相関が無いようなデータを持ってきていることが挙げられます。
深層学習の構造はどのような関数も近似できる(Universal approximator)ので、原理的にはどのような問題も最適化できるはずです。
Statistical Mechanics
以降の文章は未完です。そのうち、授業で紹介された論文を読みつつ式を追います。
(4.34), (4.35)から分配関数を計算します。
\[Z = \int d\mathbf{w} \exp \left( -\frac{\beta}{2} \sum_\mu (y_\mu - \mathbf{w} \cdot \mathbf{x}_\mu)^2\right)\]ここでエネルギー部分に
\[E(\mathbf{w}) = \frac{1}{2} \sum_\mu (y_\mu - \mathbf{w} \cdot \mathbf{x})^2 + \frac{\lambda}{2} \mathbf{w}^T \mathbf{w}\]のように余分な項を付け足すことで過適合(overfitting)を避けます。レプリカ法を用いて
\[[Z^n]_{\mathbf{C}} = \prod_a \int d\mathbf{w} \left[ \exp \left( -\frac{\beta}{2} \sum_\mu (y_\mu - \mathbf{w} \cdot \mathbf{x}_\mu)^2\right) \right]_{\mathbf{C}} \exp \left( - \frac{\lambda}{2} \mathbf{w}^T \mathbf{w} \right)\]この計算においては\(y\)も\(C\)と\(w\)の内積になっているので、注意が必要です。ここではGaussian Equivalent Theorem(GET)という計算テクニックを用います。
\[\lambda_\mu^a = \frac{1}{\sqrt{d}} \mathbf{w}_a^T \sigma (\frac{1}{\sqrt{d}} F^T \mathbf{C}_\mu^T)\]これから
\[P(\mathbb{\lambda}_\mu, \nu_\mu) \propto \exp \left( -\frac{1}{2} \sum_{a, b} \lambda_\mu^a (A_\mu^{-1})_{ab} \lambda_\mu^b- \frac{1}{2} \nu_\mu A_0^{-1} \nu_\mu - \frac{1}{2} \sum_a \nu_\mu \mathbf{B}_\mu^T \mathbf{\lambda}_\mu^a\right)\]ここで\(A_n = \frac{a^2}{d} \mathbf{w}^a \mathbf{w}^b+ \frac{b^2}{d}\mathbf{s}^a \mathbf{s}^b, A_0 = \frac{1}{d} \mathbf{w}_0^T \mathbf{w}_0, \mathbf{B}_n = \frac{b}{d} \mathbf{s}^a \cdot \mathbf{w}_0\)などです。
Appendix 1: \(0<n<1\)の系
以前の講義で\(n=0\)はquenched系、\(n=1\)のannealed系に対応すると学びました。しかし、\(0 < n <1\)の系も存在します。これをpartial annealed系と呼びます。どちらの変数も動くが、動くスピードが違う(ゆっくり動く)とイメージできます。データを変えながら最適化を行う場合には、このような中途半端な\(n\)の値の系が実際の機械学習の系ではないかとされています。
Appendix 2: レプリカ法のアプリケーション例
量子アニーリングを用いて最適化問題を解く(イジングの基底状態を求める)という応用例があることから、量子ゆらぎの計算を導入します。その時の計算方法にレプリカ法が用いられます。最近ではAdS/CFT対応の文脈でもレプリカ法が用いられており、論文数が増えていると言われています。
参考文献及びリンク